Afgelopen decennia is de zorg sterk gedigitaliseerd. Een gemiddeld ziekenhuis heeft vandaag de dag met meer dan tweehonderd IT-systemen te maken: van data-opslag tot internet en ziekenhuisnetwerk en van zorgmail tot EPD. Dat zorgt ervoor dat IT-storingen grote gevolgen kunnen hebben. In deze blog legt Manfred Rothfusz, Technisch Consultant, uit hoe je het aantal storingen binnen het ziekenhuis kunt minimaliseren met performancetesten en -monitoring.
Digital Services : country and language
Gevolgen van IT-storingen voor de patiëntveiligheid
De Onderzoeksraad voor Veiligheid (OVV): ‘Eén defect onderdeel of een verkeerde netwerkinstelling kan de primaire zorgprocessen in een ziekenhuis uren- of zelfs dagenlang stilleggen. Dit heeft gevolgen voor de kwaliteit en veiligheid van de zorg voor patiënten.’
Hoewel ieder ziekenhuis zich bewust is van het feit dat IT-problemen een keiharde impact hebben op de zorgprocessen, komen grootschalige en langdurige IT-storingen nog steeds (te) vaak voor. Sterker nog: het aantal storingen is in de afgelopen jaren zelfs licht gestegen.
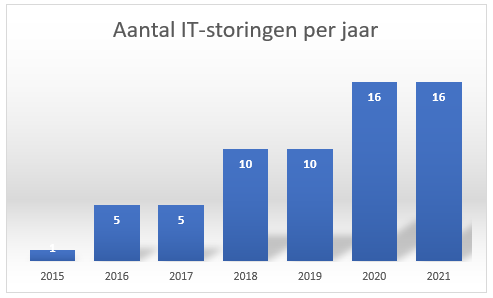
Aantal ziekenhuizen met IT-storingen in de periode 2015-2021.
Ziekenhuisgroepen waarbij meerdere locaties getroffen zijn,
zijn in deze figuur geteld als één storing.
Meer aandacht nodig voor het voorkomen en bestrijden van IT-uitval
Met alle nieuwe innovaties rondom beeldbellen, eHealth en extramuraal (samen)werken wordt de afhankelijkheid van IT binnen het ziekenhuis alsmaar groter. Uitval van systemen heeft steeds meer directe gevolgen voor de patiëntveiligheid. Het is niet voor niets dat de OVV ziekenhuizen adviseert om meer aandacht te besteden aan het voorkomen en bestrijden van IT-uitval en de gevolgen hiervan.
Het honderd procent voorkomen van IT-storingen is onmogelijk, maar door proactieve monitoring en het periodiek testen van IT-systemen in een ziekenhuis in hun samenhang kun je borgen dat kritische zorgprocessen blijven functioneren. Ook na software-updates, nieuwe releases of toevoeging van nieuwe componenten.
Meten is weten
Door proactief te monitoren en regelmatig te valideren hoe het met de IT-systemen gesteld is, minimaliseer je de kans op problemen en houd je de kwaliteit van service zo hoog mogelijk. Mocht zich toch een storing voordoen, dan is het natuurlijk heel belangrijk dat de IT-beheerafdeling zo snel mogelijk op de hoogte is, inclusief betrouwbare antwoorden op vragen als ‘hoe functioneren de systemen normaal gesproken’, ‘wat was het eerste moment dat de storing optrad’ en ‘hoe vaak treedt de storing op’. Een dergelijke performancemeting bestaat uit twee onderdelen:
- Meten in pre-productie – een testomgeving, zodat bij simulatie niet direct de ‘live’-omgeving beïnvloed wordt
- Meten in productie – de daadwerkelijke ziekenhuisomgeving
1. Meten in pre-productie
Onder pre-productie verstaan we een omgeving die niet daadwerkelijk in gebruik is, maar die daar wel heel erg op lijkt. Een dergelijke omgeving wordt gebruikt om een nieuwe oplossing of een update (grootschalig) te testen en te valideren. Die validatie kun je natuurlijk laten doen door de ziekenhuismedewerkers die het systeem daadwerkelijk gebruiken, maar efficiënter is het om gesimuleerde medewerkers – een soort virtuele medewerkers – in te zetten die je medewerkers van vlees en bloed nabootsen en load genereren.
Tijdens het testen check je zaken als capaciteit, responsetijden en functionaliteiten van nieuwe oplossingen of updates vóór deze daadwerkelijk in gebruik worden genomen. Zo kun je risico’s minimaliseren. Je kunt zo ook gecontroleerd testen hoe het staat met de redundantie van bepaalde systemen: is er, als systeem X nu uitvalt, een ander systeem beschikbaar om de taak over te nemen? Vergelijk het met een noodstroomvoorziening, die moet je ook regelmatig testen wil je er op het moment suprême echt op kunnen vertrouwen.
Een voorbeeld uit de praktijk
Een groot universitair medisch centrum nam enige tijd geleden een nieuw EPD in gebruik. Door miscommunicatie tussen netwerkbeheer en Windows-beheer, bleek een router bij een bepaalde hoeveelheid verbindingen niet optimaal te functioneren. Door met een groot aantal gesimuleerde medewerkers te testen hebben we de foutieve configuratie vooraf kunnen ontdekken en hebben we een hoop nare problemen kunnen voorkomen.
2. Meten in productie
Als een IT-systeem eenmaal in productie is genomen en binnen het landschap van een ziekenhuis draait, is het belangrijk om in de gaten te houden hoe het presteert. Als het uitvalt of niet naar verwachting presteert, moet de IT-beheerafdeling daar zo snel mogelijk van op de hoogte zijn. Door ook in de productie-omgeving te werken met gesimuleerde medewerkers die de omgeving regelmatig doormeten, ben je minder afhankelijk van meldingen van ‘echte’ zorgmedewerkers. Voor hen ligt de prioriteit immers bij het verlenen van zorg, waardoor ze niet altijd in staat zijn om bij problemen à la minute IT te informeren.
Een gesimuleerde medewerker kan aan de hand van een bepaalde drempelwaarde geautomatiseerd een notificatie geven als één of meerdere systemen niet naar verwachting functioneren. Daarbij worden alle belangrijke gegevens om een storing goed te kunnen onderzoeken, zoals tijdstippen, automatisch vastgelegd. Door op die manier zaken als netwerkstoringen of inlogproblemen vroegtijdig te constateren, kunnen ze ook eerder worden opgelost. Bovendien worden responsetijden van systemen tastbaar, doordat de gesimuleerde medewerkers ook die vastleggen. Zo zijn ze beter te beoordelen dan wanneer een ziekenhuismedewerker belt met de mededeling dat het systeem ‘traag’ is. Traag is namelijk interpretatie en kan voor iedereen anders zijn. Gesimuleerde medewerkers zorgen dus ook voor een stuk transparantie en kunnen bijdragen aan de onderbouwing van een SLA.
Een voorbeeld uit de praktijk
Het universitaire medisch centrum, uit het eerdere voorbeeld, houdt dankzij performancemonitoring en -testen met gesimuleerde medewerkers nu voortdurend in de gaten of hun IT-systemen naar behoren werken. Mocht het nu voorkomen dat een gesimuleerde medewerker inlogt en dat duurt anderhalve minuut, dan gaat er direct een alarmbel af bij IT, zodat zij proactief kunnen onderzoeken waar het probleem zit. De gesimuleerde medewerker verzamelt alle data, zodat alle historie gelijk voorhanden is. Lekker efficiënt en ze voorkomen dat de helpdesk wordt platgebeld door medewerkers die het probleem op de werkvloer ervaren – zo ver komt het als het goed is namelijk niet.
Conclusie: simuleer, valideer en constateer, want voorkomen is beter dan genezen!
Meer weten?
Benieuwd hoe jouw ziekenhuis levensbedreigende storingen kan voorkomen dankzij performancetesten en -monitoring? Lees meer over onze performance services of neem contact met ons op.



