Automating Documentation with ADF API and Python
Documentation is essential for any project and beneficial for operations. It needs to be a live entity and an ongoing activity. Writing documentation is not a one-time action anymore because it becomes outdated quickly. This article will explain how to export documentation automatically from Azure Data Factory and generate Markdown documents using Python code.
To automate the documentation generation for Azure Data Factory pipelines, we can leverage the ADF API, a set of RESTful web services Azure provides for programmatically interacting with Data Factory resources. Python, with its rich ecosystem of libraries, can be used to make API calls and process the retrieved information to create comprehensive Markdown documentation.
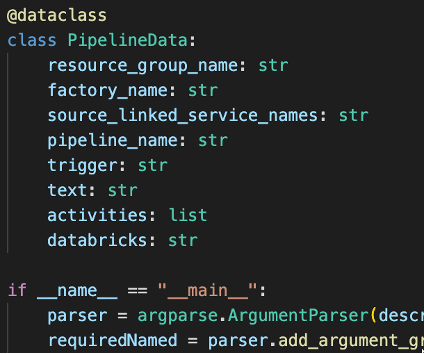
The example below is developed to document many pipelines and maintain current documentation. In the example, details such as source and target linked services, activities, secrets, and triggers are collected, processed, and generated in documentation. As a result, in generated documentation, pipelines are grouped by source-linked service and separated into individual files.




