Machine Learning with its different types of learning
- Supervised (Labeled data)
- Unsupervised (Unlabeled data)
- Semi-supervised (A mixture between labeled and unlabeled data)
- Reinforcement learning (learning from mistake)
AutoML aims to optimize and accelerate human tasks by improving everyday life. The list of examples could be very long, but I will mention a few: automatic waste classification, optimization of water filtering membranes maintenance, cyber security protocols improvement to detect attacks.
The “Auto” part refers to the automation algorithms of ML by using Machine Learning algorithms. In other words, we are taking the AI to another level, and that’s what leads the AutoML to become a hot topic in both Industry and Academia. However, the main question remains whether it is a real process or not.
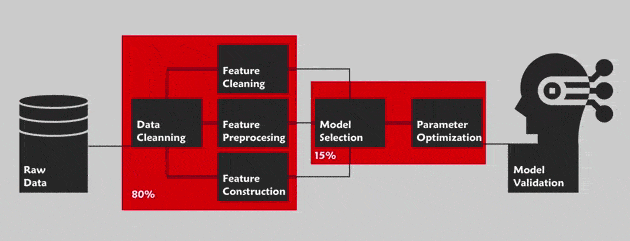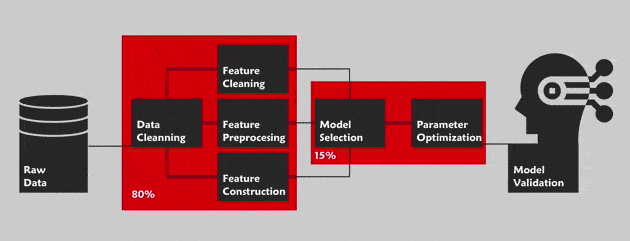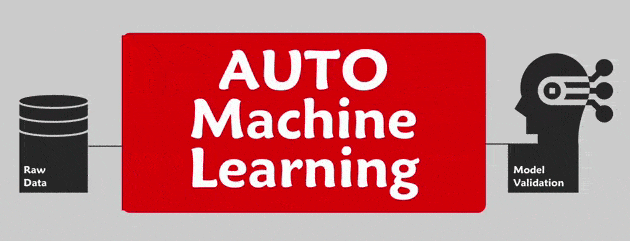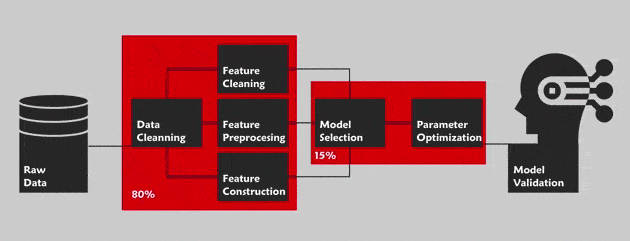
The AutoML consists in optimizing all of the pipeline for a data science project. By this, we are referring to the Cross Industry Standard Process for Data Mining (CRISP-DM) methodology with the main phases: Business understanding, data understanding, data preparation, modeling, evaluation and deployment. This methodology defines the step by step guide of this project. Outside of the “business understanding” phase ,the AutoML aims to automate the whole pipeline in order to facilitate the task to a non-expert in this field (For instance Cloud AutoML by Google for the vision).